자바 프로그램 실행 과정 및 기본 구조
-목차-
자바는 1995년 썬 마이크로시스템즈에서 발표한 객체 지향 프로그래밍 언어이다.
그 당시에 문제점 : 각각의 하드웨어 와 운영체제마다 프로그램을 개발해야 하는 번거로움
당시 인터넷이 급격하게 발전하면서 웹 어플리케이션 개발이 많이 이루어졌다.
이에 어플리케이션을 쉽게 개발할 수 있는 언어가 필요하였다.
자바는 운영체제와 하드웨어에 독립적으로 동작하는 플랫폼과
인터넷에서 동작하는 어플리케이션 개발을 위한 언어로써 탄생하게 되었다.
자바는 어떻게 독립적으로 동작하는 플랫폼을 구현할 수 있지?
자바 컴파일러는 소스 코드를 바이트 코드로 변환한다. 바이트 코드는 JVM이 이해할 수 있는 중간 코드 형태로 운영체제와 하드웨어에 독립적으로 동작한다.
JVM은 운영체제나 하드웨어에 상관없이 동일한 바이트 코드를 실행할 수 있는 플랫폼이다.
이는 JVM이 각 플랫폼에 맞게 구현되어 있기 때문에 가능하다.
JVM은 플랫폼 별로 구현된 두개의 컴포넌트로 이뤄져있다.
1)JVM 스펙에 정의된 자바 가상 머신 스펙을 준수하는 JVM 실행 엔진이다.
이 엔진은 모든 플랫폼에서 동일하게 작동하며, 바이트 코드를 실행하는 인터프리터와 JIT 컴파일러를 포함
2)각 플랫폼에 맞게 구현된 네이티브 (native code)이다. 이 코드는 운영체제와 하드웨어에 맞게 구현되어 있으며,
JVM실행 엔진과 상호작용하여 바이트 코드를 실행하며, 이러한 네이티브 코드는 다른 플랫폼에서는 동작하지 않는다
따라서 자바 어플리케이션은 운영체제나 하드웨어 상관없이 동일한 바이트 코드를 실행할 수 잇으며, 이를 가능하게 하는 것은 각 플랫폼에 맞게 구현된 JVM실행엔진과 네이티브 코드 덕이다.
자바는 실행환경(JRE) 과 개발환경(JDK)을 분리하여 제공한다. 이를 통해 자바는 사용자가 필요한 최소한의 환경만을 설치하여 애플리케이션을 실행할 수 있게되어, 플랫폼에 대한 의존성을 최소화할 수 있다.
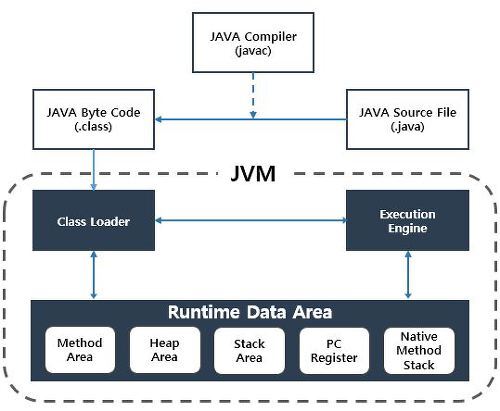
자바 컴파일 과정
자바는 OS에 독립적인 특징을 가지고 있다. 그게 가능한 이유는 JVM(Java Vitual Machine)덕분이다.
OS에 독립적으로 실행시킬 수 있는지 자바 컴파일 과정을 통해 알아보자.

자바 컴파일 순서
컴파일러가 자바소스를 바이트 코드로 변환한다. 클래스 로더가 바이트 코드를 런타임 데이터 영역에 로드시키고
로딩된 바이트 코드가 실행엔진에 의해서 실행되게 된다.
-----------------컴파일 타임 환경 -----------------------
1.개발자가 자바 소스코드(.java)를 작성한다
2.자바 컴파일러가 자바소스파일을 컴파일한다. 이때 나오는 파일은 자바 바이트코드(.class)파일로 아직 컴퓨터가 읽을수 없는 자바 가상 머신이 이해할 수 있는 코드입니다.
---------------------런타임 환경 -------------------------
3.컴파일된 바이트 코드를 JVM의 클래스 로더에게 전달한다.
4.클래스 로더는 동적로딩을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역,
즉 , JVM의 메모리에 올린다.
클래스 로더 세부 동작
로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드한다.
검증 : 자바 언어 및 JVM 명세에 명시된 대로 구성되어 있는지 검사한다.
준비 : 클래스가 필요로 하는 메모리를 할당한다.(필드,메서드,인터페이스 등등)
분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경한다.
초기화 : 클래스 변수들을 적절한 값으로 초기화 한다.
클래스 로더는 클래스파일을 동적로딩하여 메모리에 적재하는 역할
자바 언어는 객체지향 프로그래밍 언어로,클래스라는 개념을 중심으로 구성된다.해당 프로그램에서 사용되는 클래스 파일들을 클래스 로더를 통해 JVM내부로 로딩이 된다. 클래스 로더는 로딩된 클래스 파일들을 검증,로딩하며 로딩된 클래스 파일들을 JVM 내부의 메모리 영역인 메소드 영역에 저장한다.
5.실행엔진은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행한다. 이때 실행엔진은 두가지 방식으로 변경한다.
- 인터프리터 : 바이트 코드 명령어를 하나씩 읽어서 해석,실행한다. (하나하나는 빠르나, 전체적인실행속도가 느림)
- JIT 컴파일러 : 인터프리터 단점을 보완하기 위해 도입된 방식으로 바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고 이후에는 해당 메서드를 더이상 인터프리팅하지 않고, 바이너리 코드로 직접 실행하는 방식.
바이트 코드는 자바 컴파일러에 의해 생성되며, 이는 JVM에서 실행된다.
JVM은 먼저 바이트 코드를 인터프리터에 의해 해석하여 실행한다.
하지만 JVM은 바이트코드를 인터프리터만 해석하는 것보다 더 나은 성능 위해 JIT(Just In Time)컴파일러를 사용하기도 한다. JIT 컴파일러는 바이트 코드를 분석하고, 반복적으로 실행되는 코드를 네이티브 코드(native code)로 컴파일한다.
이를 통해 자바 어플리케이션은 운영 체제와 하드웨어 독립적으로 실행 될 수 있으면서도 높은 성능을 발휘할 수 있게 된다.
자바 메모리 구조
자바메모리 구조는 크게 5가지 영역으로 구분된다. 우선 스레드마다 PC Register, JVM Stack 그리고 Native Method Stack있다. 그리고 스레드 공통으로는 Heap과 Method Area가 있다.
PC Register 는 현재 수행중인 JVM 명령어가 들어있다.
JVM Stack 은 호출된 메소드의 매개변수, 지역변수, 리턴 정보들이 저장되어있다.
Native Method Stack 은 자바 외의 언어인 C, C++ 같은 것들을 수행하기 위한 영역이다.
Method Area는 클래스 별로 전역변수,정적변수, 메소드 정보들이 저장되게 된다.
Heap 영역은 런타임중 생성되는 객체들이 동적으로 할당되는 곳이다.
code,,data,heap,stack 는 운영체제에서 프로그램이 어떻게 나눠지냐에 따라서 구분되는 거다.
운영체제 메모리( code,,data,heap,stack ) 에 JVM 메모리가 올라간다. JVM만에 메모리영역이 나눠지게 된다.
Runtime Data Area
JVM이 프로세스로써 수행되기 위해 OS로부터 할당받는 메모리 영역이다.
저장 목적에 따라 다음과 같이 5개로 나눌 수 있다.
스레드별 : PC Register(명령어), Native Method Stack(자바 외 다른언어로 작성된 코드)
JVM Stack,(메소드 안에서 사용되는 값들이 저장되는 구역 ,메서드 호출 시 메서드의 스택 프레임이 생성되는 영역으로, 메서드의 지역 변수, 매개 변수, 리턴 값, 연산 도우미 값 등이 저장)
공통 : Method Area(클래스별로 저장되는 영역),
Heap(사용자에 의해 동적으로 할당된 데이터 영역, 인스턴스 객체를 저장하는 영역으로, new 키워드로 생성한 객체, 배열 등이 저장됩니다.)
JVM STACK이랑 HEAP영역이랑 비슷해 보이는데 다르다
JVM 스택과 Heap 영역은 비슷해 보일 수 있지만, 둘은 서로 다른 개념입니다. JVM 스택은 메서드 호출 시 생성되는 스택 프레임들을 저장하는 영역이고, Heap 영역은 객체와 배열 등의 인스턴스를 저장하는 영역입니다. 각각의 스택 프레임은 해당 메서드 내에서 사용되는 지역 변수와 매개 변수, 연산 도우미 값 등을 저장하고, Heap 영역은 객체를 생성하고 인스턴스 변수를 저장하는 역할을 합니다.
한마디로 HEAP 는 new 키워드로 생성하는 객체,배열을 저장하는 영억, JVM STACK은 메소드 실행하면서 매개변수가 초기화면서 메모리에 할당된다. 메서드의 지역변수,매개변수,리턴값 등이 저장된다.
4.가비지 컬렉션
GC는 JVM에서 메모리를 관리해주는 모듈이다.Heap 메모리르 재활용하기 위해서 더이상 참조되지 않는 객체들을 메모리에서 제거하는 모듈이다.개발자가 직접 메모리를 정리하지 않아도 되어서 개발속도가 향상되는 장점이 있지만 Mark and Sweep (GC의 작동원리로,데이터가 꽉차면 잠깐 멈춘 다음 데이터가 GC대상이면 삭제한다 )
이라는 과정에서 참조되지 않는 객체를 찾는 과정이 있는데, 이때 스레드가 잠깐 중단되어서 성능이 떨어진다는 단점이 있다
.
JVM에서 메모리 관리해주는 모듈
C 나 C++ 프로그래밍을 할때 메모리 누수를 막기 위해 객체를 생성한 후 사용하지 않은 객체의 메모리를 프로그래머가 직접 해제 해주어야 했다. 하지만 JAVA에서는 JVM 이 구성된 JRE가 제공되며 , 그 구성요소 중 하나인 가비리 컬렉션이 자동으로 사용하지 않는 객체를 파괴한다.
기본적으로 JVM의 메모리는 총 5가지 영역(class, stack, heap, native method, PC)으로 나뉘는데,
GC는 힙 메모리만 다룹니다
일반적으로 다음과 같은 경우에 GC의 대상이 됩니다.
- 객체가 NULL인 경우 (ex. String str = null)
- 블럭 실행 종료 후, 블럭 안에서 생성된 객체
- 부모 객체가 NULL인 경우, 포함하는 자식 객체
GC 모니터링은일반적으로 자바 가상머신(JVM)에서 자동으로 수행된다. JVM은 메모리 사용량이나 GC의 동작상황을 모니터링하고 , 필요한 경우 GC를 수행하여 메모리를 정리한다.
자바 어플리케이션에서 메모리 사용량과 GC의 동작을 모니터링하고 분석하는 프로세스이다.