대규모 트래픽일시 현 architecture의 문제점 분석 및 해결
현재 개발한 서비스 sns 어플리케이션 경우에는 기능만 집중하여 개발하였다.
대규모트랙픽이랑 코드의 최적화 되어있지 않고 기능구현중점으로 서비스 개발하였다.
그렇다면 대규모 트래픽일시 현 archtecture의 문제점 분석 및 해결법이 뭐가 있는지 확인하고 개선해보겠다.
해결법은 별다른것이 아닌 최적화가 되어있는지 확인을 해본다. 가장 쉽게 생각할 수 있는것은 코드의 중복되는 부분이 있는지 확인해보고 코드를 보았을때 어떠한 부분이 무거운 작업인지, 부하가 많이 가는 작업인지 들을 고민해볼수 있다.
1.코드의 비 최적화
2.수만은 DB IO
3.기능간의 강한 결합성
크게 위 3가지의 문제점을 확인해보면서 현 archtecture의 문제점이 무엇인지 분석해보겠다.

문제점 1. Token 인증시 user를 조회하고, 그 이후 또 user를 조회하는 구조
-회원가입을 하고 로그인할때 Token를 발급해준다.
매번 API를 조회시 그 API가 회원인경우에만 사용가능한 API의 경우에는 TOKEN이 유효한지 검증하는 로직을 거치게 된다.
여기서 문제점이 발생된다.
토큰을 인증할때 처음에 FILTER에서 토큰 유효하는 검증이 발생하고 뒤에 API 호출시 발생하는 유효검증이 발생하게 된다.두번의 DB IO가 발생한다.
1) 토큰 필터에서 토큰 유효 검증하기 위한 DB에서 USER 정보 DB IO 발생
2)API 호출시 USER의 정보 DB IO 발생
-게시글 작성 API 호출시 유정의 정보를 확인하기 위한 DB IO 발생


사실 이미 JWE TOKEN 필터를 통과를 했었기에 유저의 정보가 DB에 있다는 사실을 알수가 있다.그래서
userEntity 는 에러가 발생되지 않는다.

문제점 2. 매 API 요청시마다 조회하는 User
로그인한 유저가 게시글 작성, 댓글 작성시 할때마다 매 API마다 User를 조회하는 로직이 추가된다. 그렇지만 로그인한 유저는 이미 필터에서 검증된 유저이기에 추가로 검증하는 부분은 중복되는 부분이라고 생각된다.
문제점 3. Alarm까지 생성해야 응답을 하는 API
현 코드의 Like 구현의 순서는
1.게시글 존재 유무 확인
2.유저 존재 유무 확인
3.like 중복 확인
4.like 저장
5.그리고 alarm 저장
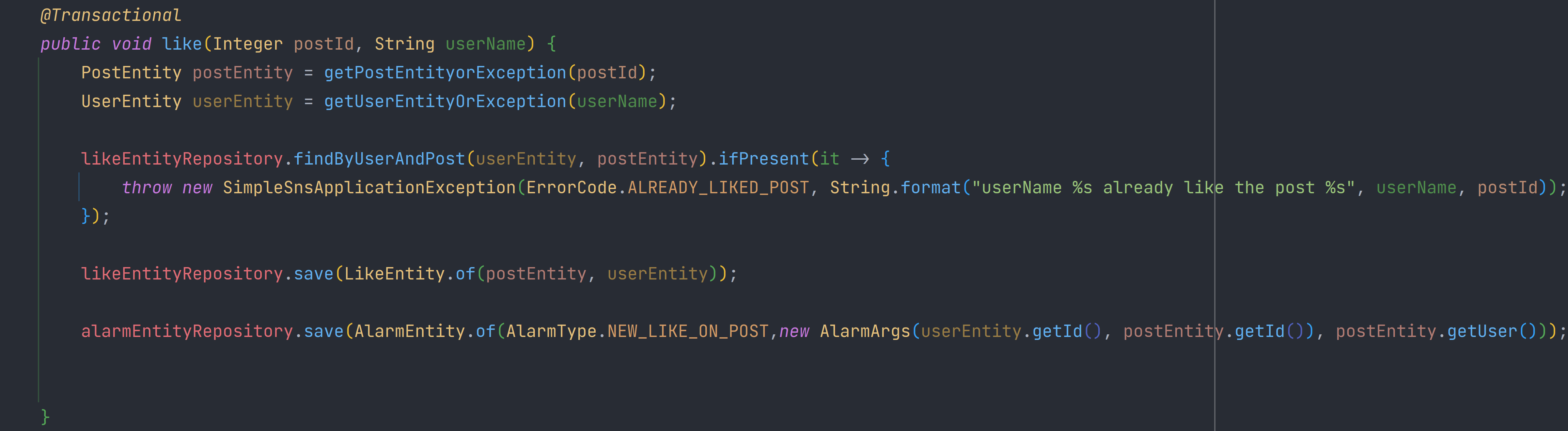
이를 비즈니스적으로 생각을 해보면 해당 like 의 메소드의 주요 핵심로직은 like를 한것이지 alram을 즉각적으로 요청을 보내줄 필요는 없다는거다.
핵심로직을 생각을 해볼시에 like의 구현의 순서를 확인해보면서 해당 로직의 로딩시간의 가치정도를 따져보면 된다.
예를 들어 ~
like의 구현순서중
1.게시글 존재 유무 확인하는 로딩이 5초가 걸린다.이 5초를 기다려야 하나??? -> 꼭 필요하다
2.유저 존재 유무 확인 " -> 꼭 필요하다
3.like 중복 확인 " -> 꼭 필요하다
4.like 저장 " -> 꼭 필요하다
5.alarm저장 " -> 5초를 기다리면서까지 필요하나?
-> 나중에도 할수 있자나?? 단순히 저장만 하고 1~2초나 나중에 알람을 보낼 수 있지 않을까?? 라고 생각을 해보면
결합정도를 느슨하게 해볼필요가 있다. 현재에는 강한 결합으로 인해 로딩과부하가 발생된다.
이를 분리해보자.
문제점 4. AlarmList API를 호출해야만 갱신되는 알람 목록
현재 알람페이지를 구성하였지만 페이지를 새로고침해야 갱신되는 알람 목록을 확인할 수 가 있다.
이게 문제점이 될 수 있는 이유는 알람이라는 기능은 서비스적으로 생각을 해보면 당연히 누군가 댓글작성, 좋아요 버튼을 눌렀을때는 조금의 지연이 있다고 하더라도 자동으로 알림이 와야 한다.
예를 들어 내가 인스트 좋아요 버튼을 누르면 알람을 받는 사람이 새로고침을 해서 받는가??? 그렇지 않다.
지연이 있다고 한들 좋아요 버튼을 누르면 알람을 받는 해당 유저에게 자동으로 알림이 가게 된다.
그렇다면 현재 API를 어떻게 구현을 해야 할까?
현재 API를 주기적으로 호출을 해야 하나??
--> 주기적으로 호출을 하게 되면 서버에 부하가 크다. 만약 알림이 없는데 굳이 호출을 할 필요가 없으니까~~
이를 효율적으로 알람호출을 할 수 있는 방법이 뭘까??
고민을 해볼수가 있다.
문제점 5. 데이터 베이스로 날라가는 Query들은 최적화가 되었을까?
현 어플리케이션은 JPA를 사용하여 서비를 개발하였다. JPA같은 경우는 내가 직접 QUERY 작성을 하는 것이 아닌 ENTITY를 바탕으로 작성한 소스를 바탕으로 쿼리가 생성되어 날라간다.
그런데 ENTITY연관관계도 있는데 내가 생각하는데로 JOIN이 되어서 쿼리가 날라가는걸까? 라는 체크를 해봐야 한다.
MYSQL 같은 경우는 쿼리를 확인할 수 있기에 그 최적화를 알 수가 있지만 JPA 같은 경우에는 아무래도 객체화를 시켜서 쿼리화를 초점을 두다보니 쿼리에 대한 최적화가 부족할 수 있다.
쿼리 최적화를 고민해봐야 한다.
해결법
1.코드의 비 최적화
2.수많은 DB IO
3.기능간의 강한 결합성

1.변하지 않는 로직을 매번 DB에서 가져올 필요가 없다. ---------- > CACHE
2.비동기처리를 통한 분산 처리진행 및 느슨한 결합 -----> Kalfka